
203 câu hỏi
Data Mining được định nghĩa là gì ?
Là một quy trình tìm kiếm, phát hiện các tri thức mới, tiềm ẩn, hữu dụng trong cơ sở dữ liệu lớn
Khai phá dữ liệu
Khai khoáng dữ liệu
Tìm kiếm thông tin trên Internet
Thuật ngữ Data Mining dịch ra tiếng Việt có nghĩa là:
Khai phá dữ liệu hoặc Khai thác dữ liệu
Khai phá luật kết hợp
Khai phá tập mục thường xuyên
Khai phá tri thức từ dữ liệu lớn
Thuật ngữ Knowledge Discovery from Databases – KDD có nghĩa là:
Trích chọn các mẫu hoặc tri thức hấp dẫn (không tầm thường, ẩn, chưa biết và hữu dụng tiềm năng) từ tập dữ liệu lớn
Khai phá dữ liệu
Khai thác dữ liệu
Tìm kiếm dữ liệu
Phát biểu nào sau đây là đúng ?
Data Mining là một bước trong quá trình khai phá tri thức-KDD
Thuật ngữ Data Mining đồng nghĩa với thuật ngữ Knowledge Discovery from Databases
Data Mining là quá trình tìm kiếm thông tin có ích trên Internet
Tiền xử lí dữ liệu là qua trình tìm kiếm thông tin có ích từ cơ sở dữ liệu lớn
Hiện nay, Data Mining đã được ứng dụng trong:
Hệ quản trị CSDL SQL Server
Hệ quản trị CSDL Access
Hệ quản trị CSDL Foxpro
Microsoft Word 2010
Thuật ngữ Tiền xử lí dữ liệu bằng tiếng Anh là:
Data Preprocessing Khoa CNTT – Data Mining 1
Data Processing
Preprocessing in Database
Data Process
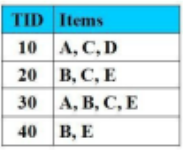
Cho CSDL Giao tác như hình vẽ, Số lượng giao dịch trong cơ sở dữ liệu là:

5
16
6
10
Cho CSDL giao dịch như hình vẽ, Độ hỗ trợ của tập mục X={A, M} là:

3 (60%)
4 (80%)
5 (100%)
2 (40%)
Thuật toán Apriori có nhược điểm chính là:
Tốn nhiều bộ nhớ và thời gian. Không thích hợp với các mẫu lớn. Chi phí để duyệt CSDL nhiều.
Không tìm được các tập thường xuyên
Kết quả của thuật toán không ứng dụng được trong các bài toán thực tế
Thuật toán quá phức tạp, khó hiểu
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%). Tập nào là tập mục thường xuyên thỏa Min_support:
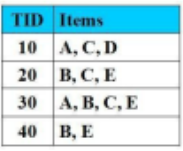
{A,C}
{D}
{A,D}
{B, C, D}
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%). Tập nào không là tập mục thường xuyên: 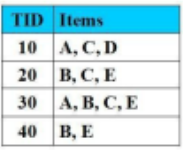
{A,C,D}
{A,E}
{A, C}
{B,E}
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%). Tập nào không là tập mục thường xuyên: 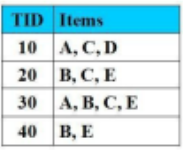
{D}
{A,E}
{A, C}
{B,E}
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%). Sử dụng thuật toán Apriori, sau lần duyệt thứ nhất, tập mục chứa 1-item bị loại bỏ là:
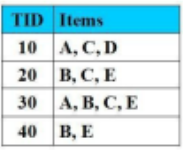
{D}
{A}
{B}
{A}, {D}
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%). Tập nào không là tập mục thường xuyên:
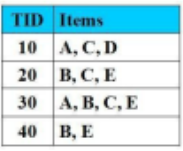
{B, D}
{A, E}
{A, C}
{B, E}
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%). Khoa CNTT – Data Mining 4 Tập nào là tập mục thường xuyên với độ hỗ trợ là = 70%
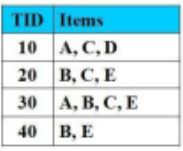
Không có tập nào
{A, E}
{A, C, D}
{B, C, D}
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%), Min_Cofidence = 50%. Luật kết hợp nào thỏa mãn các điều kiện đã cho:
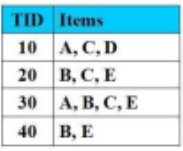
A-->C
A-->D
A--> E
AB-->C
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%), Min_Cofidence = 50%. Luật kết hợp nào thỏa mãn các điều kiện đã cho:
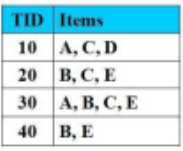
B-->E
A-->D
A--> E
AB-->C
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%), Min_Cofidence = 50%. Luật kết hợp nào thỏa mãn các điều kiện đã cho:
A-->C
A-->D
A--> E
AB-->C
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%), Min_Cofidence = 50%. Luật kết hợp nào có độ tin cậy = 100%
A-->C
A-->D
AD--> E
AB-->C
Cho tập mục thường xuyên X={A, B}, từ tập X có thể sinh ra các luật kết hợp sau:
A--> B, B--> A, không tính luật AB --> và --> AB
A-->B, B--> A, A--> và --> B
A--> B
B--> A
Cho FP-Tree như hình vẽ, có mấy đường đi kết thúc ở nút m
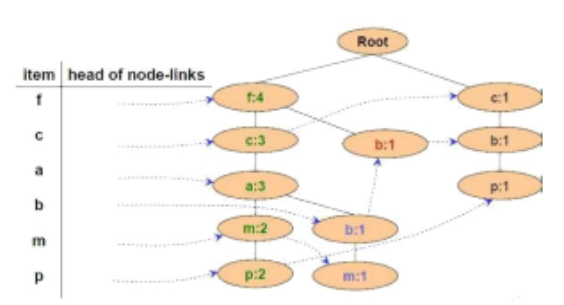
2 đường đi
1 đường đi
3 đường đi
4 đường đi
Cho FP-Tree như hình vẽ, có mấy đường đi kết thúc ở nút p
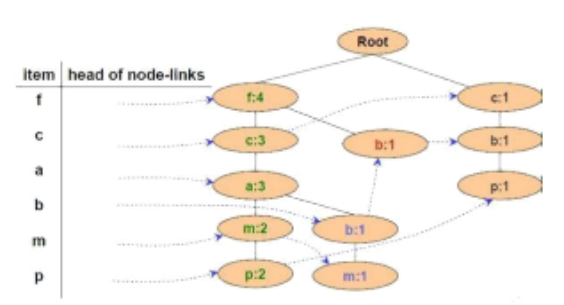
2 đường đi
1 đường đi
3 đường đi
4 đường đi
Hai thuật toán FP-Growth và Apriori dùng để:
Tìm các tập mục thường xuyên
Tìm các luật kết hợp
Tìm các tập mục có k - item
Thực hiện công việc khác
Phương pháp nào không phải là phương pháp phân lớp:
Chia các đối tượng thành từng lớp để giảng dạy
Phân lớp dựa trên Cây quyết định
Phân lớp dựa trên xác suất Bayes
Phân lớp dựa trên Mạng Nơron
Khi chọn 1 thuộc tính A để làm gốc cây quyết định. Nếu thuộc tính A có 3 giá trị thì cây quyết định có bao nhiêu nhánh?
3 nhánh
2 nhánh
Nhiều nhánh
Phải biết kết luận C có bao nhiêu giá trị thì mới phân nhánh được
Sử dụng thuật toán ILA, khi kết luận C có n giá trị thì ta cần chia bảng chứa các ví dụ học thành mấy bảng con:
n bảng con
2 bảng con
không phải chia
Thành nhiều bảng tùy theo giá trị của n
Cho giá trị của A là 3500, Sử dụng phương pháp chuẩn hóa Tỷ lệ Thập phân– decimal scale, giá trị của A sau khi chuẩn hóa là:
0.35
3.5
0.015
Giá trị khác
Gom cụm (clustering) gì:
Phân cụm dữ liệu(Data Clustering) hay phân cụm, cũng có thể gọi là phân tích cụm là quá trình chia một tập các đối tượng thực thể hay trừu tượng thành nhóm các đối tượng sao cho các phần tử trong cùng một nhóm thì có mức độ tương tự nhau hơn là giữa các phần tử của nhóm này với các phần tử của nhóm khác.
Phân cụm dữ liệu(Data Clustering) hay phân cụm, cũng có thể gọi là phân tích cụm là qúa trình chia một tập các đối tượng thực thể hay trừu tượng thành nhóm các đối tượng sao cho các phần tử khác nhóm thì có mức độ tương tự nhau hơn là giữa các phần tử trong cùng một nhóm.
Phân cụm dữ liệu(Data Clustering) hay phân cụm, cũng có thể gọi là phân tích cụm là quá trình chia một tập các đối tượng thực thể hay trừu tượng thành nhóm các đối tượng sao dễ sử dụng nhất.
Phân cụm dữ liệu(Data Clustering) hay phân cụm, cũng có thể gọi là phân tích cụm là quá trình chia các đối tượng thành từng nhóm sau cho số nhóm là ít nhất.
Thuật ngữ tiếng Anh nào có nghĩa là phân cụm dữ liệu
Data Clustering
Data Classification
Association Rule
Data Mining
Thuật ngữ tiếng Anh nào có nghĩa là Khai phá dữ liệu
Data Mining
Data Clustering
Data Classification
Association Rule
Thuật ngữ tiếng Anh nào có nghĩa là Phân lớp dữ liệu
Data Classification
Data Clustering
Data Mining
Association Rule
Có N phần tử cần chia thành 1 cụm. Hỏi có bao nhiêu cách chia cụm:
1 cách
0 cách
2 cách
N cách
Câu 41: Có N phần tử cần chia thành m cụm, với m>N. Hỏi có bao nhiêu cách chia cụm:
0 cách
m cách
2 cách
N cách
Có bao nhiêu thuật toán phân cụm:
Rất nhiều
Chỉ có 3 thuật toán Liên kết đơn, liên kết đầy đủ, k-mean
Chỉ có 2 thuật toán Liên kết đơn và liên kết đầy đủ
Chỉ có 2 thuật toán Liên kết đơn và k-mean
Trong thuật toán phân cụm k-mean, ban đầu k tâm được chọn:
Chọn ngẫu nhiên
Chọn k phần tử nằm ở tâm
Chọn k các phần tử có giá trị nhỏ nhất
Chọn k phần tử có giá trị bằng giá trị trung bình của các phần tử trong tập dữ liệu
Sử dụng thuật toán k-mean để chia N điểm vào k cụm, khi đó:
k<=N
k=N
k>N
k khác N
Quá trình khai phá tri thức trong CSDL (KDD) có thể phân chia thành các giai đoạn sau:
Trích chọn dữ liệu, tiền xử lý dữ liệu, biến đổi dữ liệu, khai phá dữ liệu, đánh giá và biểu diễn tri thức
Tiền xử lý dữ liệu, biến đổi dữ liệu, khai phá dữ liệu, đánh giá và biểu diễn tri thức
Trích chọn dữ liệu, tiền xử lý dữ liệu, biến đổi dữ liệu, khai phá dữ liệu, khai phá luật kết hợp
Tiền xử lý dữ liệu, phân lớp, phân cụm, đánh giá và biểu diễn tri thức
Các loại đặc trưng của dữ liệu:
Đặc trưng danh nghĩa, đặc trưng theo thứ tự, đặc trưng đo theo khoảng, đặc trưng đo theo tỷ lệ
Đặc trưng danh nghĩa, đặc trưng theo thứ tự, đặc trưng đo theo khoảng, đặc trưng theo khối lượng
Đặc trưng danh nghĩa, đặc trưng theo thứ tự, đặc trưng đo theo khoảng, đặc trưng theo chiều dài
Đặc trưng theo thứ tự, đặc trưng đo theo khoảng, đặc trưng đo theo tỷ lệ
Một số bài toán điển hình trong khai phá dữ liệu là:
Khai phá luật kết hợp, phân loại, phân cụm, hồi qui...
Khai phá luật kết hợp, xây dựng máy tìm kiếm...
Web mining, Text mining, mạng nơron…
Bài toán nhận dạng, bài toán tìm kiếm thông tin, bài toán lựa chọn đặc trưng...
Một số thách thức lớn trong quá trình khai phá dữ liệu là (chọn đáp án đúng nhất):
Dữ liệu quá lớn, dữ liệu bị thiếu hoặc nhiễu, sự phức tạp của dữ liệu, dữ liệu thường xuyên thay đổi...
Trình độ của con người còn hạn chế, dữ liệu không được lưu trữ tập trung...
Dữ liệu quá lớn, máy khai phá dữ liệu có tốc độ hạn chế...
Tốc độ xử lý của máy tính còn hạn chế, dữ liệu thường xuyên thay đổi...
Một số lĩnh vực liên quan đến khai phá tri thức – KDD là:
Machine Learning, Visualization, Statistics, Databases…
Machine Learning, Programming, Statistics, Databases…
Machine Learning, Visualization, Statistics, BioInfomatics…
Support Vector Machine, Clustering, Statistics, Databases…
Khai phá dữ liệu có lợi ích gì?
Cung cấp hỗ trợ ra quyết định, dự báo, khái quát dữ liệu...
Tìm kiếm các quy luật, tìm kiếm các cụm và phân loại dữ liệu
Tìm kiếm nhanh thông tin, thống kê dữ liệu, chọn đặc trưng của dữ liệu...
Tạo ra cơ sở tri thức mới, hỗ trợ dự báo thời tiết, dự báo động đất, dự báo sóng thần...
Khai phá dữ liệu có lợi ích gì?
Cung cấp hỗ trợ ra quyết định, dự báo, khái quát dữ liệu...
Tìm kiếm các quy luật, tìm kiếm các cụm và phân loại dữ liệu
Tìm kiếm nhanh thông tin, thống kê dữ liệu, chọn đặc trưng của dữ liệu...
Tạo ra cơ sở tri thức mới, hỗ trợ dự báo thời tiết, dự báo động đất, dự báo sóng thần...
Làm sạch dữ liệu (Data Cleaning) là quá trình:
Loại bỏ nhiễu và dữ liệu không nhất quán
Tìm kiếm dữ liệu có ích
Tìm kiếm dữ liệu có ích trong cơ sở dữ liệu lớn
Tổ hợp nhiều nguồn dữ liệu khác nhau
Một số ứng dụng tiềm năng của Khai phá dữ liệu:
Phân tích và quản lý thị trường, Quản lý và phân tích rủi ro, Quản lý và phân tích các sai hỏng, Khai thác Web, Khai thác văn bản (text mining)…
Tìm kiếm văn bản, Tìm kiếm hình ảnh, Tìm kiếm tri thức mới trên Internet...
Phân tích tâm lí khách hàng, Hỗ trợ kinh doanh, tối ưu hóa phần cứng máy tính...
Phân tích thị trường chứng khoán, bất động sản, tìm kiếm dữ liệu bằng các máy tìm kiếm...
Các cơ sở dữ liệu cần khai phá là:
Quan hệ, Giao tác, Hướng đối tượng, Không gian, Thời gian, Text, XML, Multi media, WWW, …
Text, XML, Multi-media, WWW, …
Cơ sở dữ liệu khách hàng, cơ sở dữ liệu nghiên cứu không gian, cơ sở dữ liệu trong ngân hàng, cơ sở dữ liệu thống kê…
Cơ sở dữ liệu tuyển sinh đại học, cơ sở dữ liệu dự báo thời tiết, cơ sở dữ liệu thống kê dân số…
Thuật ngữ Big Data có nghĩa là:
Big data nói đến các tập dữ liệu rất lớn và phức tạp tới mức các kỹ thuật IT truyền thống không xử lí nổi.
Dữ liệu rất lớn
Dữ liệu được tích hợp từ nhiều nguồn khác nhau
Dữ liệu khổng lồ trên Internet
Thuật ngữ BioInfomatics có nghĩa là
Giải quyết các bài toán sinh học bằng việc sử dụng các phương pháp của khoa học tính toán
Sinh học phân tử
Tìm kiếm dữ liệu mới từ sinh học
Khai thác các thông tin có ích trong lĩnh vực y học
Phát biểu nào sau đây là đúng
Data Mining là một bước quan trọng trong quá trình khai phá tri thức từ dữ liệu – KDD
Tiền xử lí dữ liệu là chọn ra các đặc trưng tiêu biểu trong tập dữ liệu lớn
Mọi dữ liệu đều có thể tìm kiếm được bằng máy tìm kiếm của Google
Data Mining là công cụ giúp các lập trình viên dễ dàng tìm kiếm thông tin hơn
Làm sạch dữ liệu là:
Điền giá trị thiếu, làm trơn dữ liệu nhiễu, định danh hoặc xóa ngoại lai, và khử tính không nhất quán
Chuẩn hóa và tổng hợp
Bước cuối cùng trong quá trình Data Mining
Tích hợp CSDL, khối dữ liệu hoặc tập tin phức
Các bài toán thuộc làm sạch dữ liệu là:
Xử lý giá trị thiếu, Dữ liệu nhiễu: định danh ngoại lai và làm trơn, Chỉnh sửa dữ liệu không nhất quán, Giải quyết tính dư thừa tạo ra sau tích hợp dữ liệu.
Làm trơn theo biên, phương pháp đóng thùng, điền giá trị thiếu, Giải quyết tính dư thừa tạo ra sau tích hợp dữ liệu.
Phân cụm, phân lớp, hồi quy, biểu diễn dữ liệu.
Phân cụm, tìm luật kết hợp, tìm kiếm đặc trưng
Cho một tập dữ liệu có n đặc trưng. Có bao nhiêu tập con không rỗng chứa các đặc trưng được lựa chọn:
2^n -1
2^n
Vô số tập con
n^2
Một số phương pháp loại bỏ dữ liệu nhiễu là:
Bỏ qua bản ghi có dữ liệu bị thiếu, điền giá trị thiếu bằng tay, điền giá trị tự động
Loại bỏ dựa trên quan sát, loại bỏ khi lựa chọn đặc trưng
Loại bỏ toàn bộ dữ liệu bị nhiễu và thay thế bằng tập dữ liệu mới, lựa chọn các đặc trưng quan trọng
Sử dụng các thuật toán phân lớp, phân cụm, tìm luật kết hợp
Cho bản ghi dữ liệu, giá trị của các thuộc tính như sau: X=(6, 2, 5, 7, 5, ?). Dấu hỏi là giá trị của thuộc tính bị thiếu. Sử dụng phương pháp tính trung bình giá trị của các thuộc tính của bản ghi hiện có, hãy cho biết vị trí dấu hỏi điền giá trị là bao nhiêu:
5
6
9
Giá trị khác
Khi xử lý thiếu giá trị của các bản ghi dữ liệu, phương pháp ‘Bỏ qua bản ghi có giá trị thiếu’ chỉ thích hợp khi:
Các bản ghi có dữ liệu bị thiếu chiếm tỷ lệ nhỏ trong toàn bộ dữ liệu
Các bản ghi có dữ liệu bị thiếu chiếm tỷ lệ lớn trong toàn bộ dữ liệu
Có thể bỏ qua tất cả các bản ghi bị thiếu
Không thể bỏ qua, phải tìm các giá trị để điền vào các bản ghi bị thiếu
Cho cơ sở dữ liệu giao dịch gồm N giao dịch (bản ghi). I là tập chứa tất cả các mục (item) trong CSDL. X là một tập chứa các mục thuộc I. Giao dịch hỗ trợ X là giao dịch chứa tất cả các mục có trong X. Độ hỗ trợ của tập mục X được định nghĩa là:
Support(X)=Số lượng giao dịch hỗ trợ X / N
Support(X)=Số lượng giao dịch hỗ trợ X
Support(X)=Số lượng giao dịch hỗ trợ X / N * |I|, trong đó |I| là tổng số mục trong CSDL
Support(X)=Số lượng giao dịch hỗ trợ X *100%
Cho cơ sở dữ liệu giao dịch gồm N giao dịch (bản ghi). I là tập chứa tất cả các mục (item) trong CSDL. X, Y là tập chứa các mục thuộc I. Độ tin cậy của luật kết hợp X🡪 Y được định nghĩa là:
Confidence(X🡪Y)=Số lượng giao dịch hỗ trợ cả X và Y / Số lượng giao dịch hỗ trợ X
Confidence(X🡪Y)=Số lượng giao dịch hỗ trợ X / Số lượng giao dịch hỗ trợ Y
Confidence(X🡪Y)=Số lượng giao dịch hỗ trợ cả X và Y / Số lượng giao dịch hỗ trợ Y
Confidence(X🡪Y)=Số lượng giao dịch hỗ trợ cả X và Y /N
Cho cơ sở dữ liệu giao dịch gồm N giao dịch (bản ghi). I là tập chứa tất cả các mục (item) trong CSDL. X, Y là tập chứa các mục thuộc I. Độ hỗ trợ của luật kết hợp X🡪 Y được định nghĩa là:
Support(X🡪Y)=Số lượng giao dịch hỗ trợ cả X và Y / N
Support(X🡪Y)=Số lượng giao dịch hỗ trợ cả X và Y / Số lượng giao dịch hỗ trợ Y
Support(X🡪Y)=Số lượng giao dịch hỗ trợ cả X và Y / Số lượng giao dịch hỗ trợ X
Support(X🡪Y)=Số lượng giao dịch hỗ trợ cả X / Số lượng giao dịch hỗ trợ Y
Cho cơ sở dữ liệu giao dịch gồm N giao dịch (bản ghi). I là tập chứa tất cả các mục (item) trong CSDL. Min_Supp là độ hỗ trợ tối thiểu. X là tập chứa các mục thuộc I. Tập mục X được gọi là tập mục thường xuyên (frequent itemset) nếu:
Support(X)>=Min_Supp
Support(X)<=Min_Supp
Support(X)=Min_Supp
Support(X: Min_Supp/N
Cho cơ sở dữ liệu giao dịch gồm N giao dịch (bản ghi). I là tập chứa tất cả các mục (item) trong CSDL. Min_Supp là độ hỗ trợ tối thiểu, Min_Conf là độ tin cậy tối thiểu. X, Y là tập chứa các mục thuộc I. Luật kết hợp X🡪Y được chọn nếu:
Support(X🡪Y)>=Min_Supp, Confidence(X🡪Y)>=Min_Conf
Support(X🡪Y)=Min_Supp, Confidence(X🡪Y)=Min_Conf
Support(X🡪Y)<Min_Supp, Confidence(X🡪Y)<Min_Conf
Support(X🡪Y)>Min_Supp, Confidence(X🡪Y)=Min_Conf
Cho CSDL giao dịch gồm N mục phân biệt, tổng số các tập mục được sinh ra (không tính tập rỗng) là:
2^N - 1
2^N
N
Vô số tập mục
Cho A, B, C, D là các item và A-->BC là luật kết hợp thỏa mãn độ hỗ trợ tối thiểu Min_Sup và độ tin cậy tối thiểu Min_Conf. Hãy cho biết luật kết hợp nào sau đây chắc chắn thỏa mãn Min_Sup và Min_Conf mà không cần phải tính độ hỗ trợ và độ tin cậy:
AB-->C
A-->D
ABD-->C
D-->C
Cho A, B, C, là các item và A-->BC là luật kết hợp thỏa mãn độ hỗ trợ tối thiểu Min_Sup và độ tin cậy tối thiểu Min_Conf. Ta thấy rằng luật kết hợp AB-->C cũng thỏa mãn điều kiện về độ hỗ trợ tối thiểu và độ tin cậy tối thiểu vì:
Conference(AB-->C) >= Conference(A-->BC)
Conference(AB-->C) <= Conference(A-->BC)
Conference(AB-->C: Conference(A-->BC)
Chưa kết luận được AB-->C có thỏa độ hỗ trợ tối tiểu và độ tin cậy tối thiểu hay không
Cho A, B, C, D là các mục trong cơ sở dữ liệu giao dịch. Kết luận nào sau đây là sai:
Support(ABC) < Support(ABCD)
Support(ABC) >= Support(ABCD)
Support(AB) >= Support(ABC)
Support(AB) <= Support(A)
Phát biểu nào sau đây là đúng:
Confidence(AC--> B) >= Confidence(A--> BC)
Confidence(AC--> B: Confidence(A--> BC)
Confidence(A--> AB)>=Confidence(AC-->C)
Confidence(AB--> C) >= Confidence(AC--> B)
Giả sử ta có các tập mục thường xuyên {A,B}, {A,C}, {B,D} chứa 2-item. Sử dụng thuật toán Apriori để ghép các tập mục có 2-item thành các tập mục có 3-item , các ứng viên sinh ra có 3-item là:
{A, B, C}, {A, B, D}
{A, B, C}, {A, B, D}, {A, B, C, D}
{A, B, C}, {B, C, D}
{A, B, C}, {C, B, D}
Trong thuật toán Apriori, tập mục chứa k-item được tạo ra bằng cách nào trong các cách sau:
Tạo ra từ tập chứa k-1 item bằng cách ghép 2 tập k-1 item với nhau với điều kiện là 2 tập k-1 item này phải có chung nhau k-2 item
Tổ hợp k item từ các item có trong cơ sở dữ liệu giao dịch.
Lấy ngẫu nhiên k item sau đó ghép lại với nhau.
Sinh mọi tập con có k item từ các item có trong cơ sở dữ liệu giao dịch
Cho tập L3={abc, abd, ade, ace} là các tập mục thường xuyên chứa 3-item. Để tạo các ứng viên chứa 4-item abcd, ta cần ghép các tập chứa 3-item nào với nhau?
abc và abd
abc và ade
abc và ace
abd và ade
Khẳng định nào sau đây là sai:
FP-Tree là cây nhị phân
FP-Tree là cây tổng quát
Khi thêm 1 giao dịch vào FP-Tree đều phải thêm bắt đầu từ gốc.
Bảng đầu mục – Header Table dùng để lưu 3 thông tin: Tên item, Số lượng item đó xuất hiện trong CSDL giao dịch và Con trỏ dùng để trỏ đến nút cùng tên được sinh ra đầu tiên
Có thể sử dụng phân lớp dựa trên mạng Nơron nhân tạo. Vậy mạng Nơron nhân tạo là gì?
Là mô hình toán học mô phỏng theo mạng Nơron sinh học để giải quyết các bài toán
Là mạng máy tính có tốc độ truyền thông cao
Là mạng Nơron do con người tạo ra
Là một phương pháp để phân loại Gen của các loài sinh vật
Độ phân biệt (độ lộn xộn) của kết luận C với thuộc tính A được tính theo công thức:
Gain(C,A)=Entropy(C)-Entropy(A)
Gain(C,A)=Entropy(C)+Entropy(A)
Gain(C,A)=Entropy(A)-Entropy(C)
Gain(C,A)=Entropy(C)*Entropy(A)
Kết luận nào trong các kết luận sau là sai:
Thuật toán Quilan chọn ngẫu nhiên 1 thuộc tính để làm gốc cây quyết định
Độ phân biệt (độ lộn xộn) của một thuộc tính với kết luận C cao nhất thì Entropy của nó thấp nhất
Thuật toán học khái niệm CLS chọn ngẫu nhiên 1 thuộc tính để làm gốc cây quyết định
Entropy là một số biến thiên trong đoạn [0,1].
Kết luận C gồm 2 giá trị Yes và No. Entropy(C: 1 nói nên điều gì:
Số kết luận ‘Yes’=Số kết luận ‘No’
Số kết luận ‘Yes’ =0
Số kết luận ‘No’ =0
Không kết luận được điều gì
Kết luận C gồm 2 giá trị Yes và No. Entropy(C: 0 nói nên điều gì:
Số kết luận ‘Yes’=0 hoặc Số kết luận ‘No’
Số kết luận ‘Yes’ = Số kết luận ‘No’
Số kết luận ‘No’ =1 và Số kết luận ‘Yes’ = 1
Không kết luận được điều gì
Khi sử dụng thuật toán Quilan để xây dựng cây quyết định. Tại mỗi bước của thuật toán ta chọn thuộc tính nào trong số các thuộc tính còn lại để làm gốc phân nhánh?
Thuộc tính có độ phân biệt cao nhất
Thuộc tính có độ phân biệt thấp nhất
Thuộc tính có Entropy cao nhất
Chọn ngẫu nhiên
Khi sử dụng thuật toán CLS (Concept Learning System) để xây dựng cây quyết định. Tại mỗi bước của thuật toán ta chọn thuộc tính nào trong số các thuộc tính còn lại để làm gốc phân nhánh?
Chọn ngẫu nhiên
Thuộc tính có độ phân biệt thấp nhất
Thuộc tính có Entropy cao nhất
Thuộc tính có độ phân biệt cao nhất
Entropy là một đại lượng có miền giá trị là:
[0 ; 1]
(0 ; 1)
Miền giá trị là tập số nguyên dương
Miền giá trị là tập số thực dương
Thuật toán Quilan là thuật toán dùng để:
Xây dựng cây quyết định
Tìm các luật
Tìm độ phân biệt của các thuộc tính
Giúp ta tìm ra 1 thuộc tính làm gốc cây quyết định
Độ đo ‘gần gũi’ là gì ?
Đây là một độ đo chỉ ra mức độ tương tự hay không tương tự giữa hai vector đặc trưng
Độ đo giữa 2 phần tử bất kỳ
Khoảng cách giữa 2 phần tử trong không gian
Độ đo sử dụng trong Data Mining để phân cụm dữ liệu
Độ đo ‘gần gũi’ gồm có:
Độ đo tương tự và độ đo không tương tự
Độ đo khoảng cách và độ đo tình cảm
Độ đo Ơclit và độ đo phi Ơclit
Độ đo tương tự và độ đo khoảng cách trong không gian 2 chiều
Độ đo khoảng cách trong không gian Ơclit là độ đo:
Độ đo không tương tự
Độ đo tương tự
Độ đo giữa 2 đối tượng cùng loại
Độ đo giữa 2 đối tượng khác loại
Cho 2 điểm trong mặt phẳng toạ độ Oxy, cho 2 điểm A(x1, y1), B(x2, y2). Khoảng cách Ơclit giữa 2 điểm này là:
d=sqr(sqrt(x1-x2)+sqrt(y1-y2)) trong đó sqr là hàm bình phương, sqrt là hàm lấy căn.
d=sqr(sqrt(x1+x2)+sqrt(y1+y2)) trong đó sqr là hàm bình phương, sqrt là hàm lấy căn.
d=x1*x2+y1*y2
Công thức khác
Cho hai điểm A(0,1), B(4, 4). Sử dụng độ đo khoảng cách Ơclit thì khoảng cách giữa 2 điểm là
d(A,B)=5
d(A,B)=3
d(A,B)=4
d(A,B)=1
Cho tập C={x1, x2,. ..xk} gồm k phần tử, mỗi phần tử là một vector trong không gian N chiều. Vector trung bình mC của tập C là một vector trong không gian N chiều được định nghĩa là:
mC= (x1+x2+...+xk)/k
mC= (x1+x2+...+xk)
mC= (x1+x2+...+xk)/N
mC= (x1+x2+...+xk)/k*N
Trong thuật toán phân cụm k-mean, sau khi chọn được k điểm làm tâm, phần tử x sẽ được gán vào cụm C sao cho:
Khoảng cách từ x đến tâm cụm C là nhỏ nhất
Khoảng cách từ x đến tâm cụm C là lớn nhất
Khoảng cách từ x đến tâm cụm C bằng 0
Khoảng cách từ x đến tâm cụm C bằng k
Trong thuật toán k-mean, sau khi gán các đối tượng vào k cụm cần phải:
Tính lại tâm của các cụm
Tính khoảng cách giữa các phần tử trong cụm
Tìm một số phần tử đại diện của cụm
Trộn các cụm lại với nhau để số cụm sinh ra là ít nhất
Cho các điểm A(1, 1), B(2, 1), C(4, 3), D(5, 4). Sử dụng thuật toán phân cụm k-mean để chia 4 điểm vào 2 cụm. Kết quả phân cụm là:
C1={A, B} ; C2={C, D}
C1={A, C} ; C2={B, D}
C1={A, B, C} ; C2={D}
C1={A, B, D} ; C2={C}
Cho các điểm A(1, 1), B(2, 1), C(4, 3), D(5, 4), E( 1, 0). Sử dụng thuật toán phân cụm k-mean để chia 5 điểm vào 2 cụm. Kết quả phân cụm là:
C1={A, B, E} ; C2={C, D}
C1={A, C, E} ; C2={B, D}
C1={A, B, C} ; C2={D, E}
C1={A, B, D} ; C2={C, E}
Cho cụm C gồm các điểm A(1, 1), B(2, 1), C(3,1). Giả sử đại diện của cụm là một điểm (vector trung bình). Vetor trung bình của cụm là:
mC = (2 ; 1)
mC = (2 ; 0)
mC = (2.5 ;1.5)
mC=(0 ; 0)
Cho cụm C gồm các điểm A(1, 1), B(2, 4), C(6,1). Giả sử tâm của cụm là vector trung bình. Tâm của cụm là:
mC = (3 ; 2)
mC = (2 ; 3)
mC = (2.5 ;1.5)
mC=(6 ; 1)
k-Mean phù hợp với các cụm có hình dạng nào sau đây:
Dạng hình cầu
Cụm dài và mảnh
Các cụm có các điểm phân bố ngẫu nhiên
Hình dạng bất kỳ
Phát biểu nào sau đây không là nhược điểm của thuật toán K-mean
Thuật toán khó cài đặt
Không đảm bảo đạt được tối ưu toàn cục
Khó phát hiện các loại cụm có hình dạng phức tạp và nhất là các dạng cụm không lồi
Cần phải xác định trước số cụm k
Thuật toán phân cụm k-mean dừng khi:
Không thể gán (hoặc gán lại) từng điểm vào cụm khác
Số cụm sinh ra là k
Tùy theo yêu cầu của người dùng
Khi tất cả các phần tử đã được gán vào k cụm
Hãy chọn phát biểu sai trong các phát biểu sau đây về thuật toán phân cụm k mean:
Phụ thuộc vào thứ tự các phần tử đưa vào phân cụm
Cần phải xác định trước số cụm cần sinh ra
k-mean phù hợp với các cụm có dạng hình cầu
Vector được chọn làm tâm của mỗi cụm là vector trung bình của cụm đó
Kết quả của quá trình phân cụm phân cấp là:
Một sơ đồ ngưỡng tương tự (hoặc không tương tự).
Một danh sách các cụm
Một cây nhị phân biểu diễn quá trình gom cụm
k cụm được sinh ra, với k cho trước
Chọn phát biểu sai trong các phát biểu sau:
Thuật toán phân cụm phân cấp phụ thuộc vào trình tự đưa các phần tử vào phân cụm
Cắt sơ đồ ngưỡng tương tự hoặc không tương tự tại một ngưỡng nào đó, ta sẽ được danh sách các cụm
Single Linkage, Complete Linkage là 2 trường hợp đặc biệt của thuật toán phân cấp
Kết quả phân cụm phụ thuộc vào việc chọn đặc trưng, chọn độ đo gần gũi, chọn đại diện của cụm và chọn thuật toán phân cụm
Tiến trình Khai phá tri thức – KDD gồm các bước như sau:
Lựa chọn dữ liệu, tiền xử lí dữ liệu, chuyển dạng, khai phá dữ liệu, trình diễn dữ liệu
Lựa chọn dữ liệu, chuyển dạng, khai phá dữ liệu, tiền xử lí dữ liệu, trình diễn dữ liệu
Lựa chọn dữ liệu, khai phá dữ liệu, trình diễn dữ liệu tiền, xử lí dữ liệu
Lựa chọn dữ liệu, khai phá dữ liệu, trình diễn dữ liệu
Sự bùng nổ của dữ liệu trong những năm gần đây có nhiều nguyên nhân, trong đó có những nguyên nhân sau (chọn đáp án đúng nhất):
Công nghệ phần cứng phát triển mạnh, năng lực số hóa của con người ngày càng cao, bùng nổ công nghệ mạng, tác nhân tạo mới dữ liệu ngày càng nhiều...
Khoa khọc kỹ thuật ngày càng tiến bộ, nguồn nhân lực ngành Công nghệ thông tin ngày càng đông, nhu cầu khai thác thông tin ngày càng nhiều...
Thông tin thu thập từ việc nghiên cứu các hành tinh, thông tin chống khủng bố, thông tin quảng cáo ngày càng nhiều...
Dữ liệu quảng cáo ngày càng nhiều, bùng nổ các mạng xã hội,...
Data Integeation là:
Cách kết hợp dữ liệu tìm được từ các nguồn dữ liệu khác nhau
Tích hợp thông tin khách hàng phục vụ quá trình Data Mining
Phân chia dữ liệu phục vụ quá trình Data Mining
Là bước thực hiện sau khi đã tìm kiếm tri thức mới từ dữ liệu
Phát biểu nào sai về ‘Tiền xử lí dữ liệu’:
Dữ liệu sau khi Tiền xử lí sẽ thành tri thức mới
Không có dữ liệu tốt, không thể có kết quả khai phá tốt
Phân lớn công việc xây dựng một kho dữ liệu là trích chọn, làm sạch và chuyển đổi dữ liệu —Bill Inmon
Dữ liệu có chất lượng cao nếu như phù hợp với mục đích sử dụng trong điều hành, ra quyết định, và lập kế hoạch.
Các bài toán chính trong ‘Tiền xử lí dữ liệu’ là:
Làm sạch dữ liệu, Tích hợp dữ liệu, Chuyển dạng dữ liệu, Rút gọn dữ liệu, Rời rạc dữ liệu
Làm sạch dữ liệu, Tích hợp dữ liệu, Chuyển dạng dữ liệu, Rời rạc dữ liệu
Phân lớp, Tìm luật kết hợp, Gom cụm
Lựa chọn đặc trưng, Tìm thuật toán để Khai phá dữ liệu
Xếp thùng - Binning - là phương pháp rời rạc hóa đơn giản nhất. Phương pháp này gồm có:
Phân hoạch cân bằng bề rộng Equal-width và Phân hoạch cân bằng theo chiều sâu Equal-depth
Xếp thùng theo chiều sâu và Xếp thùng làm trơn theo giá trị nhỏ nhất
Làm trơn theo giá trị lớn nhất và làm trơn theo giá trị nhỏ nhất
Làm trơn theo biên phải và làm trơn theo biên trái
Phương pháp Xếp thùng - Binning là phương pháp:
Sắp xếp dữ liệu tăng dần và chia đều vào các thùng, sau đó sử dụng phương pháp làm trơn theo trung bình, theo biên, theo trung tuyến.
Chia đều dữ liệu vào các thùng, sau đó sử dụng phương pháp làm trơn theo trung bình, theo biên, theo trung tuyến.
Sắp xếp dữ liệu tăng dần và chia vào các thùng, mỗi thùng có số phần tử tùy ý, sau đó sử dụng phương pháp làm trơn theo trung bình, theo biên, theo trung tuyến.
Sắp xếp dữ liệu giảm dần và chia đều vào N thùng, loại bỏ các thùng không cần thiết
Cho tập dữ liệu được xếp theo giá: 4, 8, 9, 15, 21, 21, 24, 25, 26, 28, 29, 34. Chia tập dữ liệu trên thành 3 thùng. Kết quả chia thùng theo chiều sâu là:
Bin 1: 4, 8, 9, 15; Bin 2: 21, 21, 24, 25; Bin 3: 26, 28, 29, 34
Bin 1: 4, 4, 4, 4; Bin 2: 21, 21, 21, 21; Bin 3: 26, 26, 26, 26
Bin 1: 4, 4, 4, 15; Bin 2: 21, 21, 25, 25; Bin 3: 26, 26, 26, 34
Bin 1: 15, 15, 15, 15; Bin 2: 23, 23, 23, 23; Bin 3: 29, 29, 29, 29
Cho tập dữ liệu được xếp theo giá: 4, 8, 9, 15, 21, 21, 24, 25, 26, 28, 29, 34. Chia tập dữ liệu trên thành 3 thùng theo chiều sâu. Kết quả chia thùng làm trơn theo trung bình là:
Bin 1: 9, 9, 9, 9; Bin 2: 23, 23, 23, 23; Bin 3: 29, 29, 29, 29
Bin 1: 4, 4, 4, 4; Bin 2: 21, 21, 21, 21; Bin 3: 26, 26, 26, 26
Bin 1: 4, 4, 4, 15; Bin 2: 21, 21, 25, 25; Bin 3: 26, 26, 26, 34
Bin 1: 15, 15, 15, 15; Bin 2: 23, 23, 23, 23; Bin 3: 29, 29, 29, 29
Cho tập dữ liệu được xếp theo giá: 4, 8, 9, 15, 21, 21, 24, 25, 26, 28, 29, 34. Chia thành 3 thùng theo chiều sâu. Kết quả phương pháp chia thùng làm trơn theo biên là:
Bin 1: 4, 4, 4, 15; Bin 2: 21, 21, 25, 25; Bin 3: 26, 26, 26, 34
Bin 1: 4, 4, 4, 4; Bin 2: 21, 21, 21, 21; Bin 3: 26, 26, 26, 26
Bin 1: 9, 9, 9, 9; Bin 2: 23, 23, 23, 23; Bin 3: 29, 29, 29, 29
Bin 1: 15, 15, 15, 15; Bin 2: 23, 23, 23, 23; Bin 3: 29, 29, 29, 29
Phương pháp xếp thùng phân hoạch cân bằng theo bề rộng là:
Chi miền giá trị thành N đoạn có độ dài như nhau nhau sẽ được xếp vào cùng 1 thùng
Chia miền xác định thành N đoạn ‘’đều nhau về số lượng’’ các đoạn có xấp xỉ số ví dụ mẫu.
Lựa chọn số phần tử ngẫu nhiên và xếp và N thùng
Các phần tử có giá trị như
Trong quá trình Tiền xử lí dữ liệu người ta thường dùng một số phương pháp chuẩn hóa dữ liệu sau:
Min-Max, z-Score, Tỷ lệ thập phân – decimal scale
2NF, 3NF, BCNF
Đưa về hệ đếm thập phân, Hệ nhị phân, hệ Hecxa
Chuẩn hóa về dữ liệu văn bản, hình ảnh, âm thanh
Một số chiến lược rút gọn dữ liệu là:
Tập hợp khối dữ liệu, Giảm đa chiều – loại bỏ thuộc tính không quan trọng, Nén dữ liệu, Giảm tính số hóa – dữ liệu thành mô hình, Rời rạc hóa và sinh cây khái niệm
Tìm kiếm thêm thông tin có ích, xây dựng cây quyết định, phân nhóm dữ liệu
Phân lớp dữ liệu, tìm đặc trưng của dữ liệu, loại bỏ nhiễu
Loại bỏ phần tử ngoại lai, tìm các dữ liệu quan trọng, đưa về mô hình toán học
Cho miền giá trị từ 12000 đến 98000, Sử dụng phương pháp Min-Max để chuẩn hóa về đoạn [0.0 ; 1.0]. Giá trị 73000 được chuẩn hóa là:
0.716
0.800
0.500
Giá trị khác
Cho miền giá trị từ 120 đến 980, Sử dụng phương pháp Min-Max để chuẩn hóa về đoạn [0.0 ; 10]. Giá trị 550 được chuẩn hóa là:
5.0
8.0
9.0
Giá trị khác
Cho miền giá trị của A từ -986 đến 917, Sử dụng phương pháp chuẩn hóa Tỷ lệ Thập phân– decimal scale, miền giá trị của A sau khi chuẩn hóa là:
- 0.986 đến 0.917
0.0 đến 1.0
0.0 đến 9.17
Giá trị khác
Cho giá trị của A là 1500, Sử dụng phương pháp chuẩn hóa Tỷ lệ Thập phân– decimal scale, giá trị của A sau khi chuẩn hóa là:
0.15
1.5
0.015
Giá trị khác
Phát biểu nào đúng về Phương pháp phân tích thành phần chính (Principal Component Analysis-PCA):
Chỉ áp dụng cho dữ liệu số và dùng khi số chiều vector lớn
Chỉ áp dụng cho dữ liệu văn bản và dùng khi số chiều vector lớn
áp dụng cho mọi loại dữ liệu
Tìm đặc trưng quan trọng của tập dữ liệu
Phát biểu nào đúng về Phương pháp phân tích thành phần chính (Principal Component Analysis-PCA:
Cho N vector dữ liệu k-chiều, tìm c (<= k) vector trực giao tốt nhất để trình diễn dữ liệu. Tập dữ liệu gốc được rút gọn thành N vector dữ liệu c chiều: c thành phần chính (chiều được rút gọn). Mỗi vector dữ liệu là tổ hợp tuyến tính của các vector thành phần chính.
Cho N vector dữ liệu k-chiều, tìm c (<= k) vector đại diện để trình diễn dữ liệu. Tập dữ liệu gốc được rút gọn thành N vector dữ liệu c chiều: c thành phần chính (chiều được rút gọn). Mỗi vector dữ liệu là tổ hợp tuyến tính của các vector thành phần chính.
Cho N vector dữ liệu k-chiều, tìm c (<= k) vector trực giao tốt nhất để trình diễn dữ liệu. Tập dữ liệu gốc được rút gọn thành N vector dữ liệu k chiều: k thành phần chính (chiều được rút gọn). Mỗi vector dữ liệu là tổ hợp tuyến tính của các vector thành phần chính.
Cho N vector dữ liệu k-chiều, tìm c (<= k) vector để trình diễn dữ liệu. Tập dữ liệu gốc được rút gọn thành 1 vector dữ liệu c chiều: c thành phần chính (chiều được rút gọn). Mỗi vector dữ liệu là tổ hợp tuyến tính của các vector thành phần chính.
Rời rạc hóa là:
Rút gọn số lượng giá trị của thuộc tính liên tục bằng cách chia miền giá trị của thuộc tính thành các đoạn. Nhãn đoạn sau đó được dùng để thay thế giá trị thực.
Đưa dữ liệu về dạng số nhị phân
Biểu diễn dữ liệu thành dạng dữ liệu không liên tục
Chuyển đổi dữ liệu sang dạng sóng điện từ
Cho L là tập mục thường xuyên, S là tập con của L thì với mọi tập con S’ của S ta có:
Conference(S’-->L-S) <= Conference(S-->L-S)
Conference(S’-->L-S: Conference(S-->L-S)
Conference(S’-->L-S) > Conference(S-->L-S)
Không so sánh được Conference(S’-->L-S) và Conference(S-->L-S)
Cho X, Y là các tập mục, X là tập con của Y thì ta có:
Support(X)>=Support(Y)
Support(X)<=Support(Y)
Support(X) =Support(Y)
Không so sánh được Support(X) và Support(Y)
Cho X={A,B}, Y={A, B, C} là các tập mục, ta có:
Support(X)>=Support(Y)
Support(X)<=Support(Y)
Support(X) =Support(Y)
Không so sánh được Support(X) và Support(Y)
Cho X không là tập mục thường xuyên thì với mọi tập Y chứa X ta có kết luận:
Y không là tập mục thường xuyên
Y là tập mục thường xuyên
X là tập mục thường xuyên
Không thể kết luận được điều gì
Cho X ={A,B,C} là tập mục thường xuyên, Y={A, B} ta có kết luận:
Y là tập mục thường xuyên
Y không là tập mục thường xuyên
C là tập mục thường xuyên
X không là tập mục thường xuyên
Kết luận nào sau đây là sai:
Tập con của một tập mục thường xuyên KHÔNG là tập mục thường xuyên
Tập con của một tập mục thường xuyên là tập mục thường xuyên
Nếu luật kết hợp A-->BC thỏa mãn điều kiện của bài toán thì AB-->C cũng là luật kết hợp thỏa mãn điều kiện của bài toán
Cho tập mục X={X1, X2, …, Xn}. Nếu tất cả các mục Xi trong X đều không là tập mục thường xuyên thì mọi tập con Y của X cũng không là tập mục thường xuyên.
Cho X ={A, B} không là tập mục thường xuyên, Y = {A, B, C} ta có kết luận:
Y không là tập mục thường xuyên
Y là tập mục thường xuyên
X là tập mục thường xuyên
C không là tập mục thường xuyên
Cho X ={X1, X2, …, Xn } là tập các mục. Y là tập con của X. Nếu tất cả các mục Xi đều không là tập mục không thường xuyên thì ta có kết luận:
Y không là tập mục thường xuyên
Y là tập mục thường xuyên
X là tập mục thường xuyên
Tập X – Y là tập mục thường xuyên
Ý tưởng chính của thuật toán Apriori là:
Tạo ra các tập phổ biến (thường xuyên) có 1 item, rồi tiếp đến là 2 items, 3 items... cho đến khi chúng ta tạo ra tập phổ biến của mọi kích thước. Mỗi tập item được tạo ra phải được tính toán độ hỗ trợ và độ tin cậy. Tập k-item được tạo ra từ tập k-1 items. Tạo danh sách các item dự kiến của tập k-items bằng cách hợp từng đôi một tập k-1 items có trong danh sách.
Tạo ra các tập phổ biến (thường xuyên) có 1 item, rồi tiếp đến là 2 items, 3 items... cho đến khi chúng ta tạo ra tập phổ biến của mọi kích thước. Tập k item được tạo ra từ tập k-1 items. Tạo danh sách các item dự kiến của tập k-items bằng cách hợp từng đôi một tập k-1 items có trong danh sách. Loại bỏ các tập item không thỏa độ hỗ trợ và độ tin cậy
Tạo bảng chứa các item phổ biến, loại bỏ các item không phổ biến. Giả sử có k item là ứng viên. Tính các tập mục mà mỗi mục có số lượng phần tử là tổ hợp chập 1, 2, 3, … k của k item. Loại bỏ các item không thỏa mãn độ hỗ trợ và độ tin cậy.
Lần lượt tạo ra danh sách các item dự kiến của tập k-items bằng cách hợp từng đôi một tập k-1 items có trong danh sách. Loại bỏ các tập item không thỏa độ hỗ trợ và độ tin cậy.
Cho tập mục thường xuyên X có độ dài k (k mục), từ tập X có thể sinh ra bao nhiêu luật kết hợp:
2^k-2, không tính luật X và X
2^k không tính luật X và X
k luật
Vô số luật kết hợp
Cho tập mục thường xuyên X={A, B, C}, từ tập X có thể sinh ra bao nhiêu luật kết hợp:
6 luật, không tính luật X và X
8 luật, không tính luật X và X
3 luật
1 luật
Cho tập mục thường xuyên X={A, B, C, D}, từ tập X có thể sinh ra bao nhiêu luật kết hợp:
14 luật, không tính luật X và X
16 luật, không tính luật X
3 luật
1 luật
Cho 3 điểm x, y, z. Độ đo khoảng cách d phải thỏa mãn các điều kiện nào:
d(x,y)>0 ; d(x,y)=d(y,x) ; d(x,y) =0 ; d(x,y)<=d(x,z)+d(z,y)
d(x,y)>=0 ; d(x,y)<=d(x,z)+d(z,y)
d(x,y)>=0 ; d(x,y)=d(y,x) ; d(x,x) =0 ; d(x,y)<=d(x,z)+d(z,y)
d(x,y)>=0 ; d(x,x) =0 ; d(x,y)<=d(x,z)+d(z,y)
Khi chọn đại diện cho cụm, có thể chọn các đại diện sau:
Đại diện điểm, đại diện siêu cầu
Đại diện siêu phẳng, đại diện điểm
Đại diện điểm, đại diện siêu phẳng và đại diện siêu cầu
Đại diện siêu cầu, đại siêu phẳng
Có N phần tử cần chia thành m cụm, mỗi cụm có ít nhất 1 phần tử. Gọi S(N,m) là số cách chia N phần tử vào m cụm. Công thức nào sau đây cho ta tổng số cách chia cụm:
S(N, m) = m.S(N, m) + S(N - 1, m - 1)
S(N, m) = N.S(N - 1, m) + S(N - 1, m - 1)
S(N, m) = m.S(N - 1, m) + S(N - 1, m - 1)
S(N, m) = S(N - 1, m) + m.S(N - 1, m - 1)
Có N phần tử cần chia thành 2 cụm, mỗi cụm có ít nhất 1 phần tử. Công thức nào sau đây cho ta tổng số cách chia cụm:
S(N,2) = 2^N - 1
S(N,2) = 2^(N-1)
S(N,2) = 2^(N-1) - 1
S(N,2) = 2^N
Có N phần tử cần chia thành 2 cụm, mỗi cụm có ít nhất 1 phần tử. Công thức nào sau đây cho ta tổng số cách chia cụm:
S(N,2) = 2^N - 1
S(N,2) = 2^(N-1)
S(N,2) = 2^(N-1) - 1
S(N,2) = 2^N
Có 4 phần tử cần chia thành 2 cụm, mỗi cụm có ít nhất 1 phần tử. Hỏi có bao nhiêu cách chia cụm:
16 cách
15 cách
7 cách
1 cách
Có 5 phần tử cần chia thành 2 cụm, mỗi cụm có ít nhất 1 phần tử. Hỏi có bao nhiêu cách chia cụm:
7 cách
32 cách
15 cách
1 cách
Hãy chọn định nghĩa đúng về Ma trận không tương tự:
Cho tập X gồm N phần tử {x1, x2, …, xN}, mỗi phần tử là một vector. Ma trận không tương tự P(X) là ma trận cấp N N mà phần tử nằm ở vị trí (i, j) có giá trị là i*j
Cho tập X gồm N phần tử {x1, x2, …, xN}, mỗi phần tử là một vector. Ma trận không tương tự P(X) là ma trận cấp N N mà phần tử nằm ở vị trí (i, j) bằng 0
Cho tập X gồm N phần tử {x1, x2, …, xN}, mỗi phần tử là một vector. Ma trận không tương tự P(X) là ma trận cấp N N mà phần tử nằm ở vị trí (i, j) bằng độ không tương tự d(xi,xj) giữa hai vector xi và xj.
Cho tập X gồm N phần tử {x1, x2, …, xN}, mỗi phần tử là một vector. Ma trận không tương tự P(X) là ma trận cấp N N mà phần tử nằm trên đường chéo chính bằng 0, các phần tử khác có giá trị bất kỳ
Phát biểu nào sau đây không đúng về Ma trận không tương tự:
Là ma trận đối xứng qua đường chéo chính
Là ma trận cho biết độ không tương tự giữa 2 phần tử bất kỳ
Các phần tử nằm trên đường chéo chính bằng có giá trị 0
Là ma trận mà các phần tử trên đường chéo chính bằng 1
Sơ đồ gần gũi là :
Sơ đồ gần gũi là một sơ đồ xét mức độ gần gũi ở đó hai cụm được trộn với nhau tạo thành sơ đồ hình cây
Sơ đồ gần gũi là một sơ đồ xét mức độ gần gũi biểu diễn mối quan hệ giữa các phần tử trong quá trình phân cụm
Sơ đồ gần gũi là sơ đồ không tương tự
Sơ đồ gần gũi là một sơ đồ xét mức độ gần gũi ở đó hai cụm được trộn với nhau ở lần đầu tiên. Khi sử dụng độ đo không tương tự (tương tự), sơ đồ gần gũi được gọi là một sơ đồ không tương tự (tương tự).
Độ phức tạp của thuật toán k-Mean là:
O(n+k+t) trong đó n là số phần tử cần phân cụm, k là số cụm, t là số lần lặp
O(n^2) trong đó n là số phần tử cần phân cụm
O(n) trong đó n là số phần tử cần phân cụm
O(n*k*t) trong đó n là số phần tử cần phân cụm, k là số cụm, t là số lần lặp
Phát biểu nào đúng về thuật toán liên kết đơn:
Chọn 2 cụm gần nhau nhất Ci, Cj để trộn với nhau thành cụm Cp. Khoảng cách giữa cụm mới Cp và các cụm còn lại Cq là d(Cp,Cq)=Max{d(Ci,Cq); d(Cj,Cq)}
Chọn 2 cụm xa nhau nhất Ci, Cj để trộn với nhau thành cụm Cp. Khoảng cách giữa cụm mới Cp và các cụm còn lại Cq là d(Cp,Cq)=Min{d(Ci,Cq); d(Cj,Cq)}
Chọn 2 cụm xa nhau nhất Ci, Cj để trộn với nhau thành cụm Cp. Khoảng cách giữa
Chọn 2 cụm gần nhau nhất Ci, Cj để trộn với nhau thành cụm Cp. Khoảng cách giữa cụm mới Cp và các cụm còn lại Cq là d(Cp,Cq)=Min{d(Ci,Cq); d(Cj,Cq)} cụm mới Cp và các cụm còn lại Cq là d(Cp,Cq)=Max{d(Ci,Cq); d(Cj,Cq)}
Cho tập ví dụ học như bảng. Có bao nhiêu thuộc tính để phân lớp ?
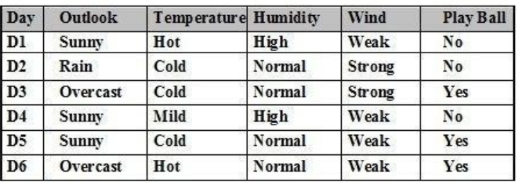
4 thuộc tính
3 thuộc tính
5 thuộc tính
6 thuộc tính
Cho tập ví dụ học như bảng. Thuộc tính kết luận Play Ball có bao nhiêu giá trị: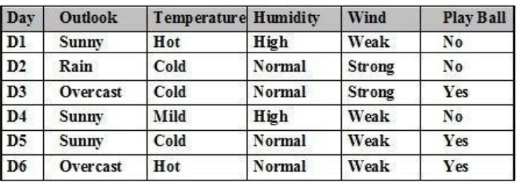
2 giá trị
3 giá trị
5 giá trị
1 giátrị
Cho tập ví dụ học như bảng. Các thuộc tính dùng để phân lớp là: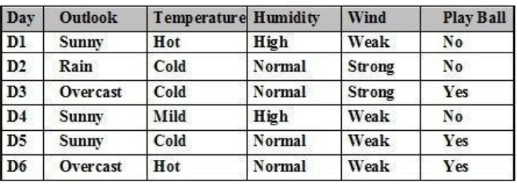
Outlook, Temperature, Humidity, Wind
Outlook, Temperature, Humidity, Wind, Play Ball
Day, Outlook, Temperature, Humidity, Wind
Day, Outlook, Temperature, Humidity, Wind, Play Ball
Cho tập ví dụ học như bảng. Sử dụng thuật toán ILA, cần chia bảng ví dụ học này thành mấy bảng con: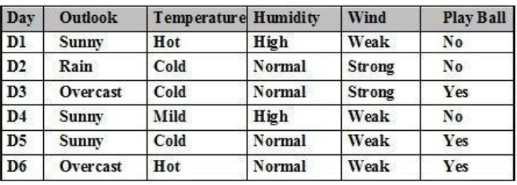
2 bảng
3 bảng
không cần chia
Tùy theo thuộc tính được chọn
Cho tập dữ liệu X={x1, x2, x3, x4, x5} và ma trận không tương tự như hình. Khoảng cách giữa 2 phần tử x1 và x2 bằng bao nhiêu:
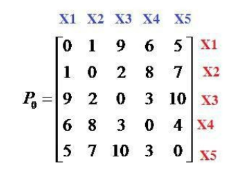
bằng 1
bằng 2
bằng 0
bằng 9
Cho tập dữ liệu X={x1, x2, x3, x4, x5} và ma trận không tương tự như hình. Khoảng cách giữa 2 phần tử x1 và x5 bằng bao nhiêu:
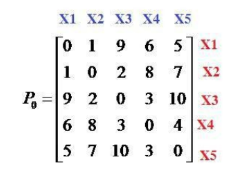
bằng 5
bằng 2
bằng 0
bằng 9
Cho tập dữ liệu X={x1, x2, x3, x4, x5} và ma trận không tương tự như hình. Sử dụng thuật toán liên kết đơn (Single Linkage), bước đầu tiên 2 phần tử nào được chọn để gom thành 1 cụm:
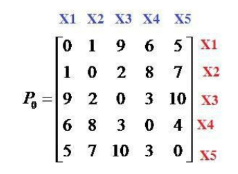
x1 và x2
x1 và x3
x2 và x3
x3 và x5
Cho tập dữ liệu X={x1, x2, x3, x4, x5} và ma trận không tương tự. Sử dụng thuật toán liên kết đầy đủ (Complete Linkage), bước đầu tiên 2 phần tử nào được chọn để gom thành 1 cụm:
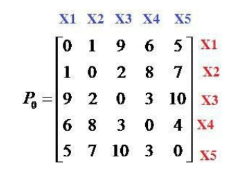
x1 và x2
x1 và x3
x2 và x3
x3 và x5
Cho sơ đồ ngưỡng không tương tự như hình vẽ. Cắt sơ đồ tại ngưỡng bằng 2.5 hỏi có mấy cụm được sinh ra:
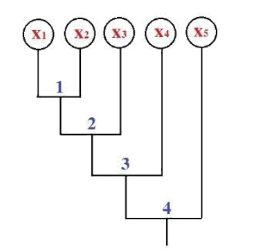
3 cụm
2 cụm
1 cụm
4 cụm
Cho sơ đồ ngưỡng không tương tự như hình vẽ. Cắt sơ đồ tại ngưỡng bằng 5 hỏi có mấy cụm được sinh ra:
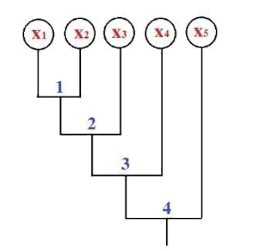
1 cụm
2 cụm
3 cụm
4 cụm
Cho sơ đồ ngưỡng không tương tự như hình vẽ. Cắt sơ đồ tại ngưỡng bằng 3.5 hỏi có mấy cụm được sinh ra:
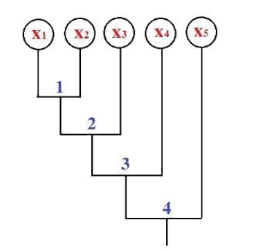
2 cụm
3 cụm
1 cụm
4 cụm
Cho sơ đồ ngưỡng không tương tự như hình vẽ. Cắt sơ đồ tại ngưỡng bằng 1.5 hỏi có mấy cụm được sinh ra:
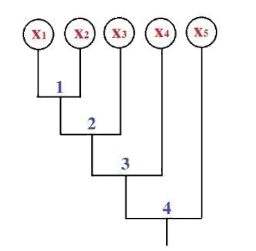
4 cụm
2 cụm
1 cụm
5 cụm
Cho sơ đồ ngưỡng không tương tự như hình vẽ. Cắt sơ đồ tại ngưỡng bằng 0.5 hỏi có mấy cụm được sinh ra:
5 cụm
2 cụm
1 cụm
4 cụm
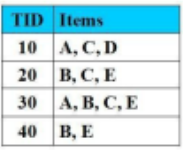
Cho CSDL giao dịch như hình vẽ. Độ hỗ trợ tối thiểu Min_Support = 3 (60%) và độ tin cậy tối thiểu Min_Confidence = 100%. Các tập mục thường xuyên có 1 mục thỏa mãn Min_Supp là:

F:4, C:4, A:3, C:3, M:3, P:3
C:4, A:3, C:3, M:3, P:3
F:4, C:4
A:3, C:3, M:3, P:3
Cho CDSL giao dịch như hình vẽ, Độ hỗ trợ tối thiểu Min_Support = 3 (60%) và độ tin cậy tối thiểu Min_Confidence = 100%.
 Tập mục thường xuyên có 4 mục thỏa mãn Min_Supp là:
Tập mục thường xuyên có 4 mục thỏa mãn Min_Supp là:
FCAM:3
FCAM:2
FC:4
FCAM:4
Cho CSDL giao dịch như hình vẽ. Độ hỗ trợ tối thiểu Min_Support = 3 (60%) và độ tin cậy tối thiểu Min_Confidence = 100%.
 Cơ sở điều kiện của nút M là:
Cơ sở điều kiện của nút M là:
{F:2, C:2, A:2} và { F:1, C:1, A:1, B:1}
{F:2, C:2, A:2}
F:1, C:1, A:1
F: 3, C:3, A:3
Cho CSDL giao dịch như hình vẽ. Độ hỗ trợ tối thiểu Min_Support = 3 (60%) và độ tin cậy tối thiểu Min_Confidence = 100%.
 Cơ sở điều kiện của nút M là:
Cơ sở điều kiện của nút M là:
{F:2, C:2, A:2, M:2} và { C:1, B:1}
{F:2, C:2, A:2, M:2}
C:3
F: 3, C:3, A:3
Cho CDSL giao dịch như hình vẽ. Độ hỗ trợ tối thiểu Min_Support = 3 (60%) và độ tin cậy tối thiểu Min_Confidence = 100%.
 Cây điều kiện FP của P là:
Cây điều kiện FP của P là:
{C:3}| p
{CF:3}|p
{C:4}|p
Cây điều kiện là rỗng
Cho CSDL giao dịch như hình vẽ. Độ hỗ trợ tối thiểu Min_Support = 3 (60%) và độ tin cậy tối thiểu Min_Confidence = 100%.
 Cây điều kiện FP của A là:
Cây điều kiện FP của A là:
{F:3, C:3}| p
{CF:3}|p
{C:4}|p
Cây điều kiện là rỗng
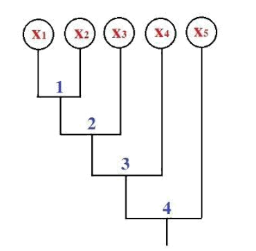
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%), Min_Cofidence = 50%.
 Luật kết hợp nào không thỏa mãn điều kiện đề bài:
Luật kết hợp nào không thỏa mãn điều kiện đề bài:
BA-->E
BC -->E
C--> E
B-->C
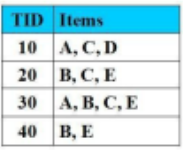
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%), Min_Cofidence = 50%.
 Luật kết hợp nào có độ tin cậy = 100%
Luật kết hợp nào có độ tin cậy = 100%
B-->E
A-->D
C--> E
AB-->C
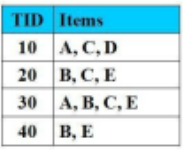
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%), Min_Cofidence = 50%.
 Luật kết hợp nào có độ tin cậy = 75%
Luật kết hợp nào có độ tin cậy = 75%
B-->CE
A-->D
C--> E
AB-->C
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%).
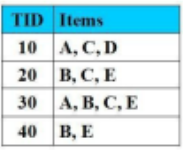 Tập nào là tập mục thường xuyên với độ hỗ trợ là 50%:
Tập nào là tập mục thường xuyên với độ hỗ trợ là 50%:
{A, C}
{A, E}
{A, C, D}
{B, C, D}
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%).
 Tập nào là tập mục thường xuyên có độ hỗ trợ cao nhất:
Tập nào là tập mục thường xuyên có độ hỗ trợ cao nhất:
{B, E}
{A, E}
{A, C, D}
{B, C, D}
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%).
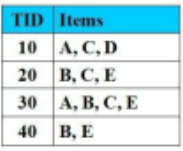 Tập nào là tập mục thường xuyên với độ hỗ trợ là 100%:
Tập nào là tập mục thường xuyên với độ hỗ trợ là 100%:
Không có tập nào
{A, E}
{A, C, D}
{B, E}
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%).
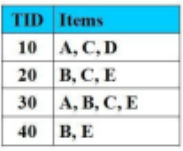 Tập nào là tập mục thường xuyên với độ hỗ trợ là 25%:
Tập nào là tập mục thường xuyên với độ hỗ trợ là 25%:
{A, C, D}
{A, C}
{E, B}
{B, C}
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%), Min_Cofidence = 50%.
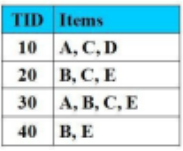 Các luật kết hợp nào có độ tin cậy = 100%
Các luật kết hợp nào có độ tin cậy = 100%
{BC-->E, B-->E}
A-->D
AC--> E
B-->C
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%).
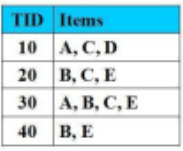 Sử dụng thuật toán Apriori, sau lần duyệt thứ nhất, các danh sách L1 chứa các tập mục thường xuyên có 1-item được tạo ra là
Sử dụng thuật toán Apriori, sau lần duyệt thứ nhất, các danh sách L1 chứa các tập mục thường xuyên có 1-item được tạo ra là
L1={{A}, {B}, {C}, {E}}
L1={{A}, {B}, {C}, {D}}
L1={{A}, {B}, {D}, {E}}
L1={{A}, {D}, {C}}
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%).
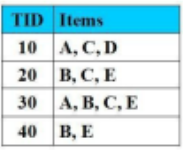 Tập nào là tập mục thường xuyên với độ hỗ trợ là = 70%
Tập nào là tập mục thường xuyên với độ hỗ trợ là = 70%
Không có tập nào
{A, E}
{A, C, D}
{B, C, D}
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%).
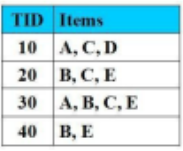 Sử dụng thuật toán Apriori để tìm các tập mục thường xuyên, số lần duyệt CSDL là:
Sử dụng thuật toán Apriori để tìm các tập mục thường xuyên, số lần duyệt CSDL là:
3 lần
2 lần
4 lần
1 lần
Cho FP-Tree như hình vẽ, mũi tên nét đứt biểu thị cho:
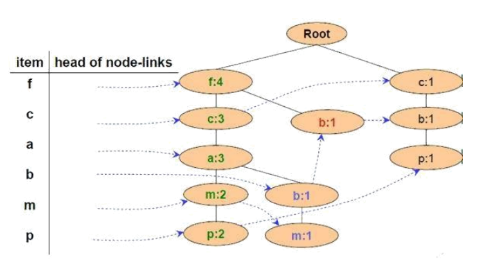
Con trỏ xuất phát từ bảng đầu mục, trỏ vào nút sinh ra đầu tiên có cùng tên. Nút sinh ra sau có con trỏ từ nút cùng tên sinh ra ngay trước đó trỏ vào
Đường đi trên cây
Nút sinh ra sau trỏ vào nút cùng tên sinh ra trước
Hướng để duyệt cây
Cho FP-Tree như hình vẽ, cơ sở điều kiện của nút P là: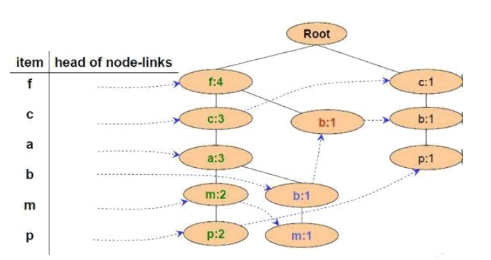
{f:2, c:2, a:2, m:2} và {c:1, b:1}
{f:3, c:3, a:3, m:2}
{f:4, c:3, a:3, m:2}
{f:2, c:2, a:2, m:2, p:2} và {c:1, b:1, p:1}
Cho FP-Tree như hình vẽ, cơ sở điều kiện của nút M là: 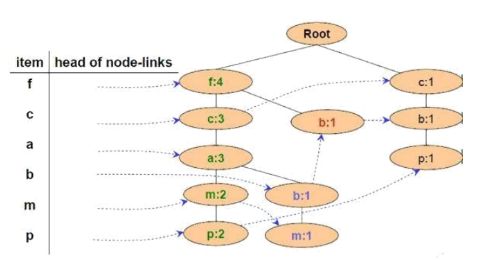
{f:2, c:2, a:2}, {f:1, c:1, a:1, b:1}
{f:4, c:4, a:3}, {f:4, c:3, a:3, b:1}
{f:2, c:2, a:2, m:2}, {f:1, c:1, a:1, b:1, m:1}
{f:2, c:2, a:2, m:2, p:2} , {c:1, b:1, p:1}
Cho FP-Tree như hình vẽ, cơ sở điều kiện của nút a là: 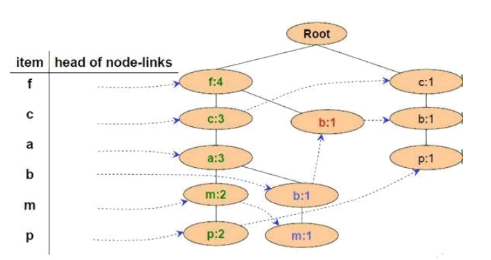
{f:3, c:3}
{f:4, c:3}
{f:4, c:3, a:3}
{f:3, c:3, a:3
Cho cây quyết định như hình vẽ. Hãy cho biết Refund=’No’, MarSt = ‘Married’, TaxInc=’80K’ thì kết luận có giá trị gì?
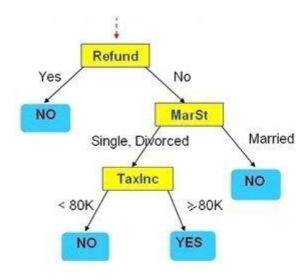
No
Yes
Không phân lớp được
Thiếu thông tin để kết luận
Cho cây quyết định như hình vẽ. Hãy cho biết Refund=’Yes’, MarSt = ‘Married’, TaxInc=’40K’ thì kết luận có giá trị gì?
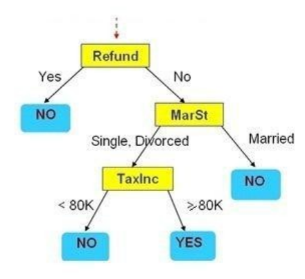
No
Yes
Không phân lớp được
Thiếu thông tin để kết luận
Cho cây quyết định như hình vẽ. Hãy cho biết Refund=’No’, MarSt = ‘Single’, TaxInc=’140K’ thì kết luận có giá trị gì?
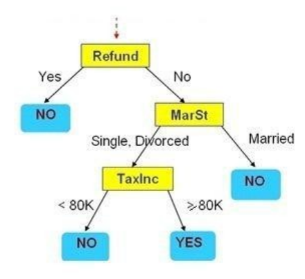
Yes
No
Không phân lớp được
Thiếu thông tin để kết luận
Cho cây quyết định như hình vẽ. Hãy cho biết Refund=’No’, MarSt = ‘Single’, TaxInc=’80K’ thì kết luận có giá trị gì?
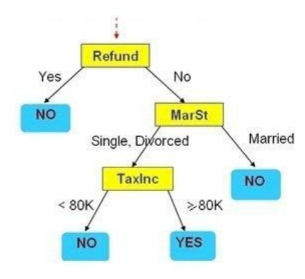
Yes
No
Không phân lớp được
Married
Cho cây quyết định như hình vẽ. Có bao nhiêu luật sinh ra từ cây quyết định trên:
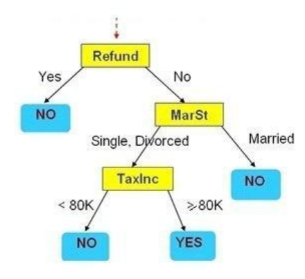
4 luật
2 luật
1 luật
Nhiều luật
Cho tập ví dụ học như bảng. Entropy của kết luận C= Play Ball là:
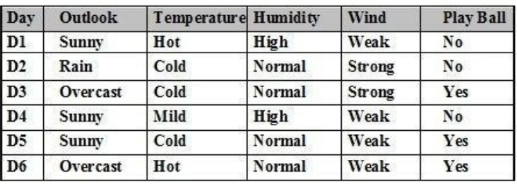
Entropy(C)=1
Entropy(C)=3
Entropy(C)=0.5
Entropy(C)=6
Cho tập ví dụ học như bảng. Entropy của thuộc tính Outlook = ‘Sunny’ là:
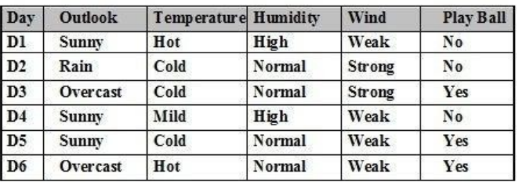
Giá trị khác
Entropy(Outlook = ‘Sunny’)=1
Entropy(Outlook = ‘Sunny’)=0.5
Entropy(Outlook = ‘Sunny’)=0
Cho tập ví dụ học như bảng. Entropy của thuộc tính Outlook là:
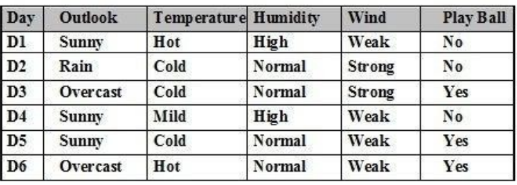
Giá trị khác
Entropy(Outlook)=1
Entropy(Outlook)=0.5
Entropy(Outlook)=0
Cho tập ví dụ học như bảng. P(Play Ball= ‘Yes’ | Outlook=’Overcast’) là: 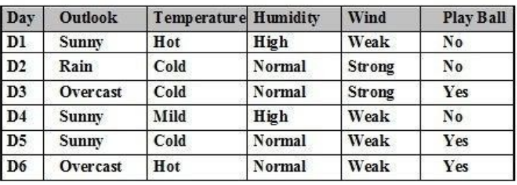
2/3
1/3
0/3
Giá trị khác
Cho tập ví dụ học như bảng. P(Play Ball= ‘No’ | Outlook=’Overcast’) là:
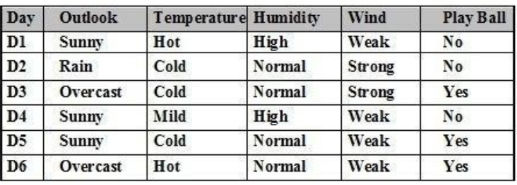
0/3
1/3
2/3
Giá trị khác
Cho tập ví dụ học như bảng. P(Play Ball= ‘No’ | Wind =’Weak’) là:
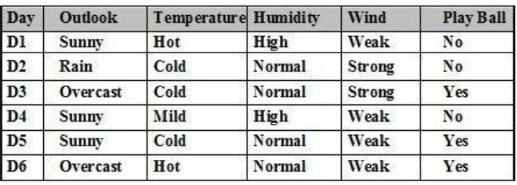
2/3
1/3
0/3
Giá trị khác
Cho tập ví dụ học như bảng. P(Play Ball= ‘No’) là: 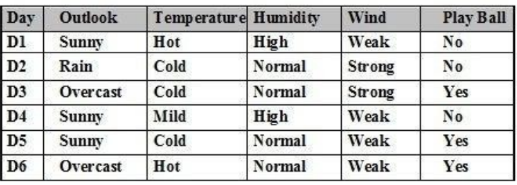
1/2
1/3
0/3
Giá trị khác
Cho tập ví dụ học như bảng. P(Wind= ‘Weak’) là:
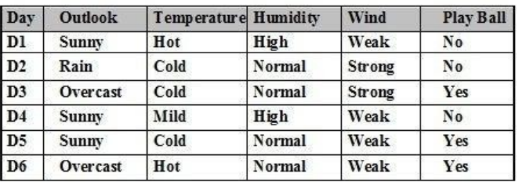
4/6
3/6
2/6
Giá trị khác
Cho tập ví dụ học như bảng. Sử dụng thuật toán ILA. Có bao nhiêu tổ hợp gồm có 1 thuộc tính:
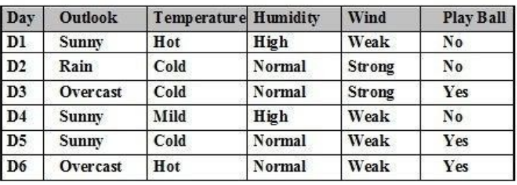
4 tổ hợp
5 tổ hợp
6 tổ hợp
2 tổ hợp
Cho tập ví dụ học như bảng. Sử dụng thuật toán ILA. Có bao nhiêu tổ hợp gồm có 2 thuộc tính phân biệt:
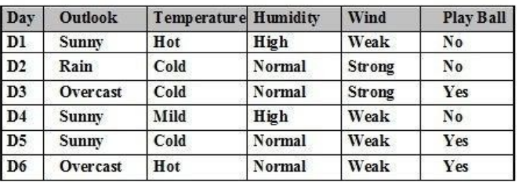
6 tổ hợp
5 tổ hợp
4 tổ hợp
2 tổ hợp
Cho tập ví dụ học như bảng. Sử dụng thuật toán ILA. Có bao nhiêu tổ hợp gồm có 3 thuộc tính phân biệt:
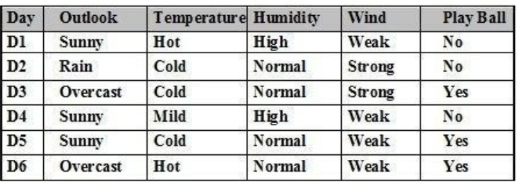
4 tổ hợp
1 tổ hợp
6 tổ hợp
2 tổ hợp
Cho tập ví dụ học như bảng. Sử dụng thuật toán ILA. Có bao nhiêu tổ hợp gồm có 4 thuộc tính phân biệt:
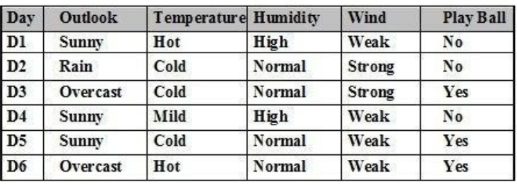
1 tổ hợp
4 tổ hợp
6 tổ hợp
2 tổ hợp
Cho tập dữ liệu X={x1, x2, x3, x4, x5} và ma trận không tương tự như hình. Sử dụng thuật toán liên kết đơn (Single Linkage), sau khi gom x1 và x2 thành cụm C={x1, x2} thì khoảng cách giữa cụm C và x3 bằng bao nhiêu:
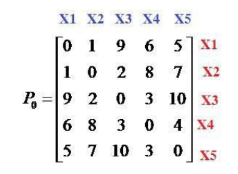
bằng 2
bằng 3
bằng 0
bằng 9
Cho tập dữ liệu X={x1, x2, x3, x4, x5} và ma trận không tương tự như hình. Sử dụng thuật toán liên kết đơn (Single Linkage), sau khi gom x1 và x2 thành cụm C={x1, x2} thì khoảng cách giữa x3 và x4 bằng bao nhiêu:
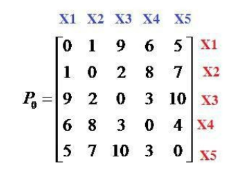
bằng 3
bằng 2
bằng 0
bằng 9
Cho tập dữ liệu X={x1, x2, x3, x4, x5} và ma trận không tương tự. Sử dụng thuật toán liên kết đầy đủ (Complete Linkage), sau khi gom x1 và x2 thành cụm C={x1, x2} thì khoảng cách giữa cụm C và x3 bằng bao nhiêu:
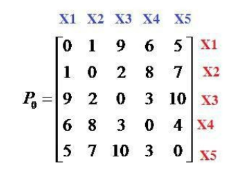
bằng 9
bằng 3
bằng 1
bằng 2
Cho tập dữ liệu X={x1, x2, x3, x4, x5} và ma trận không tương tự như hình. Sử dụng thuật toán liên kết đơn (Single Linkage). Bước đầu tiên ta gom x1, x2, vào cụm C1, ma trận không tương tự P1 sinh ra là ma trận cấp mấy:
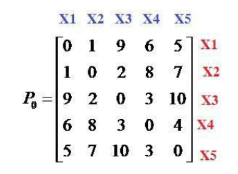
cấp 4
cấp 5
cấp 1
cấp 3
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%).
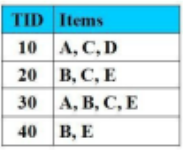 Sử dụng thuật toán Apriori, sau lần duyệt thứ hai, danh sách L2 chứa các tập mục thường xuyên có 2-item được tạo ra là:
Sử dụng thuật toán Apriori, sau lần duyệt thứ hai, danh sách L2 chứa các tập mục thường xuyên có 2-item được tạo ra là:
L2={{A,C}, {B,C}, {B,E}, {C,E}}
L2={{ A,D}, {B,D}, {B,E}, {C,E}}
L2= {{B,C}, {B,E}, {C,E}}
L2= {{A,C}, {C,E}}
Cho CSDL giao dịch như hình vẽ với Min_Support = 2 (50%).
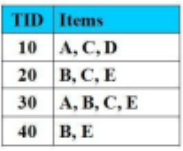 Sử dụng thuật toán Apriori, cho L2={{A,C}, {B,C}, {B,E}, {C,E}} là danh sách các tập mục thường xuyên có 2-item. Giả sử tập mục {A,B} và {A,E} không là tập mục thường xuyên. Sau khi ghép các tập mục thường xuyên 2-item với nhau để được danh sách L3 chứa các tập mục thường xuyên có 3-item, L3 là:
Sử dụng thuật toán Apriori, cho L2={{A,C}, {B,C}, {B,E}, {C,E}} là danh sách các tập mục thường xuyên có 2-item. Giả sử tập mục {A,B} và {A,E} không là tập mục thường xuyên. Sau khi ghép các tập mục thường xuyên 2-item với nhau để được danh sách L3 chứa các tập mục thường xuyên có 3-item, L3 là:
L3={{B, C, E}}
L3={{A,B, C} và {A,C,E}}
L3={{A,C,E} và {B,C,E }}
L3={{A,B,C,}}
Cho FP-Tree như hình vẽ, cây điều kiện FP của nút f là: 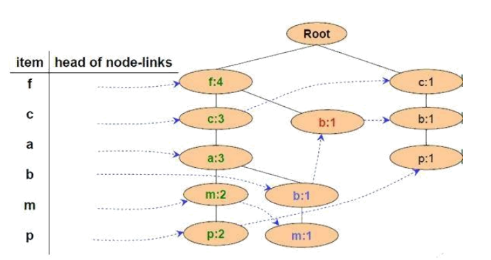
Cây rỗng
{f:4}
{f:4, c:1}
{f:3, c:3, a:3
Cho FP-Tree như hình vẽ, cây điều kiện FP của nút a là: 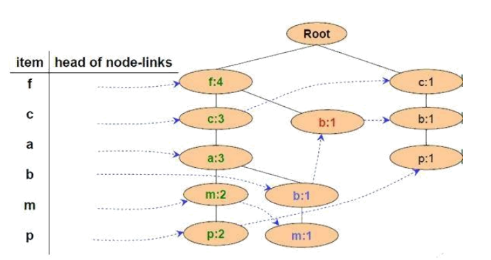
{f:4, c:3}
{f:3, c:3}
{f:4, c:3, a:3}
{f:3, c:3, a:3
Cho đồ thị như hình vẽ. Từ đồ thị ta thấy:
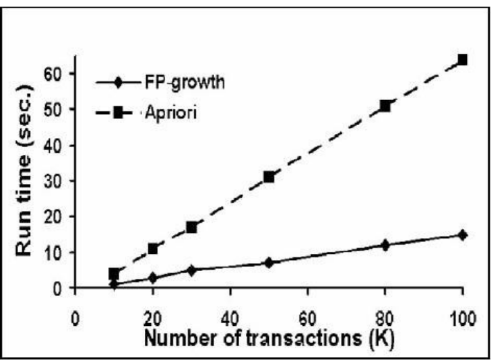
Với cùng số lượng giao dịch như nhau, thời gian thực thi của thuật toán FP-Growth luôn nhiều hơn thời gian thực thi của thuật toán Apriori
Với cùng số lượng giao dịch như nhau, thời gian thức thi thuật toán FP-Growth luôn ít hơn thời gian thực thi thuật toán Apriori
Thuật toán Apriori thực hiện nhanh hơn thuật toán FP-Growth
Hai thuật toán FP-Growth và Apriori đều thức thi với thời gian rất nhỏ.
Cho đồ thị như hình vẽ. Nhận xét nào sau đây là sai: 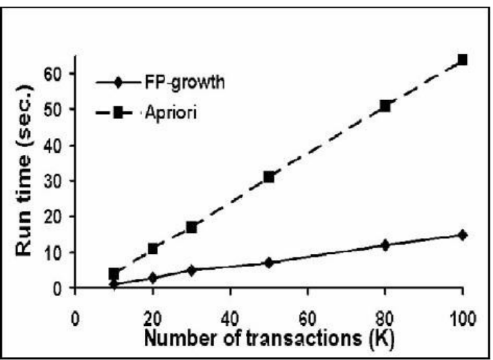
Với cùng số lượng giao dịch như nhau, thời gian thức thi thuật toán FP-Growth luôn ít hơn thời gian thực thi thuật toán Apriori
Thuật toán Apriori thực hiện nhanh hơn thuật toán FP-Growth
Khi số lượng giao tác rất nhỏ, thời gian thực thi của 2 thuật toán FP-Growth và Apriori là tương đương
Thuật toán FP-Growth thực hiện nhanh hơn thuật toán Apriori
Cho đồ thị như hình vẽ, đồ thị trên biểu diễn gì ?
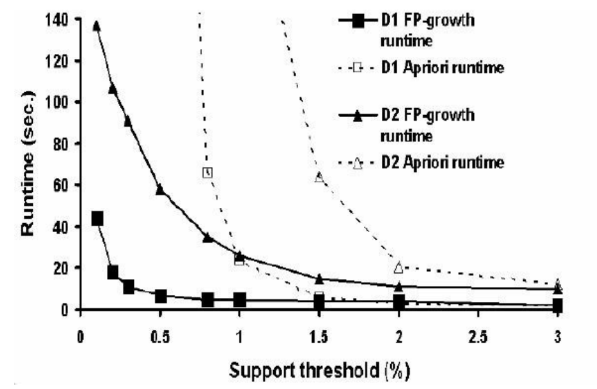
So sánh giữa Thời gian thực thi (tính bằng giây) của 2 thuật toán FP-Growth và Apriori trên 2 Database D1 và Database D2
So sánh giữa Thời gian thực thi (tính bằng giây) của 2 thuật toán FP-Growth và Apriori theo ngưỡng của độ hỗ trợ trên 2 Database D1 và Database D2
So sánh 2 thuật toán FP-Growth và Apriori theo ngưỡng độ tin cậy
Mối quan hệ giữa 2 thuật toán FP-Growth và Apriori
Cho đồ thị như hình vẽ. Từ đồ thị ta thấy: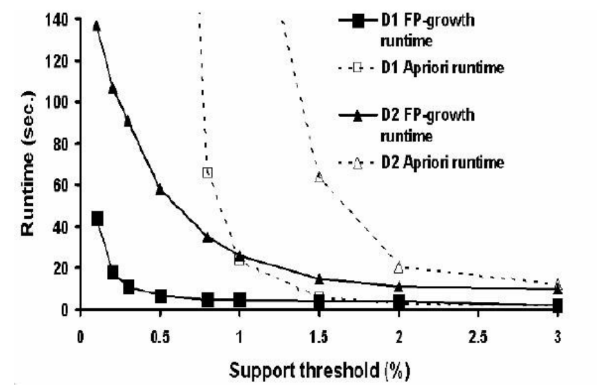
Với cùng ngưỡng của độ hỗ trợ, thời gian thực thi của thuật toán FP-Growth luôn nhiều hơn thời gian thực thi của thuật toán Apriori
Với cùng ngưỡng của độ hỗ trợ, thời gian thức thi thuật toán FP-Growth luôn ít hơn thời gian thực thi thuật toán Apriori
Thuật toán Apriori thực hiện nhanh hơn thuật toán FP-Growth
Hai thuật toán FP-Growth và Apriori đều thức thi với thời gian rất nhỏ.